This blog post is the fourth in a series of posts about STAR voting. If you haven’t read the previous entries, I recommend you start with the first entry before reading this one.
Previously I explained the importance of pre-election polls and the advantages that STAR polls have over other types of polls. I mentioned at the end that many of the properties that make STAR a good method for polling also make it a good method for choosing winners, and in this post I will justify the claim that STAR voting picks good winners. But first, we’ll have to discuss what it even means for a winner to be good in the context of single-winner elections. There are two major schools of thought on this, majoritarianism and utilitarianism, and I will start with the former.
Majoritarianism says that a candidate is good if they are preferred by over half of the voters, i.e. if they have majority support. This sounds pretty straightforward until you consider just what it means to be supported by a voter. Does being supported mean being that voter’s first choice? If so, then it’s impossible to guarantee a majority winner, and most competitive elections with more than two candidates—the elections where the choice of voting method matters most—won’t have a majority winner. Thus, most majoritarians turn to the notion of a pairwise majority instead.
Read more
I’ve discussed how STAR voting is simple, how its ballot design is superb, and how it leads to better pre-election polling. But in this post I will cover what is by far the most important aspect of this bright idea: BRANDING.
Once upon a time, there was a voting method called score-runoff voting. It was a pretty good voting method, all things considered. It produced very accurate results when tested, and its hybrid nature seemed like it might have the potential to unite the voting reform movement behind it. But there was one major problem: its name sucked.
To be fair, this is true for most voting methods. But it doesn’t have to be. Using the revolutionary technique of BRANDING, the uninspiring score-runoff voting method became the illustrious STAR voting method that you know and love. BRANDING stands for Beguiling Relatable Advertisement Notably Demands Increases in Noticed Greatness, and that’s exactly how it works. The name of the voting method itself becomes a persuasive advertisement that relates the method to the great things that voters already know about, and in doing so, it highlights those positive traits and focuses the attention on them.
Read more
This blog post is the third in a series of posts about STAR voting. If you haven’t read the previous entries, I recommend you start with the first entry before reading this one.
Last post I explained why the 5-star ballot format used by STAR voting is superior to other commonly proposed ballot formats. In this post I’ll explain how the ballot format and voting method can be adapted for use in pre-election polls, and I’ll go over the advantages of doing so. At the time of writing no one has ever conducted a STAR voting pre-election poll, and neither the Equal Vote Coalition nor STAR Voting Action have set a standard for how this would be done. However, there is a straightforward means of transforming the STAR voting method into a pre-election poll method, and it’s this polling method that I’ll be discussing here.
A STAR voting pre-election poll, or STAR poll for short, begins by having poll respondents rate the candidates using the same 0-5 scale that STAR voting uses. Once all responses have been collected, the poll results can be calculated. These results consist of two parts. The first is the average score of each candidate. While STAR voting uses total scores to determine the finalists, it makes more sense to report average scores since they are independent of the number of respondents. This is analogous to how single-choice plurality voting elects the candidate with the greatest total number of votes, but poll and election results are commonly reported as percentages rather than totals.
Read more
This blog post is the second in a series of posts about STAR voting. If you haven’t read the previous entry, I recommend you do so before starting this one.
In the previous post I made the case that STAR voting is simple enough to be a viable option for voting method reform, but I didn’t explain why STAR voting would be worth adopting. I want to start that explanation by talking about the ballot type that STAR voting uses. Often referred to as “the 5-star ballot”, it is a rated ballot with a scale of 0-5. This means that unlike with RCV ballots, you are free to rate candidates equally and to skip ratings as you like.
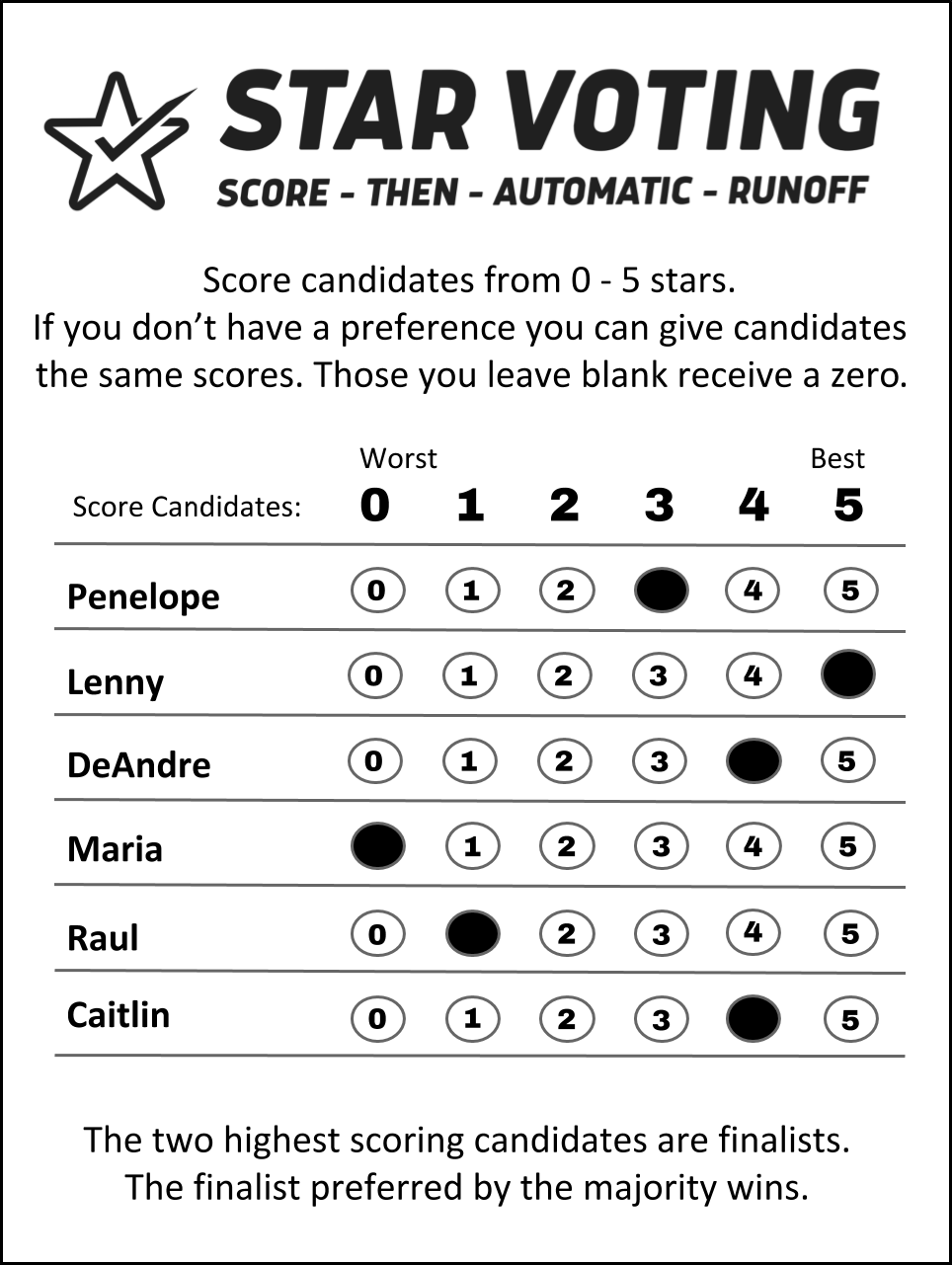
An example STAR ballot
Read more
I am a big supporter of STAR voting as a practical reform for single-winner elections in the United States. Under STAR voting, voters rate each candidate on a scale from 0 to 5, the two candidates with the highest total scores become finalists, and whichever finalist is rated higher on the most ballots wins. This is where the full name—Score Then Automatic Runoff—comes from; the first round of tallying chooses the finalists based on their score totals, and then the second round of tallying is an automatic runoff with each ballot counting for the finalist that voter preferred (or counting as an abstention if the voter liked both finalists equally).
There are a lot of reasons that I like this method, but one important reason is how simple it is. As you saw above, I can describe the entire method in a single sentence. Many other competing reforms like single-winner ranked choice voting can only be partially explained in a single sentence. STAR isn’t the simplest voting reform out there—that honor goes to approval voting—but I think a lot of people overestimate its complexity. Ranked choice voting, the most popular reform option in the U.S., is much more complex than STAR. If ranked choice voting can make as much progress as it has, then STAR is more than simple enough to be a viable reform, and anyone dismissing it on complexity grounds is doing it a disservice.
Read more